nodejs-single-threaded
简介
Node.js是在单线程里运行。你不能并行任何代码, 下面的例子会阻塞 5s。
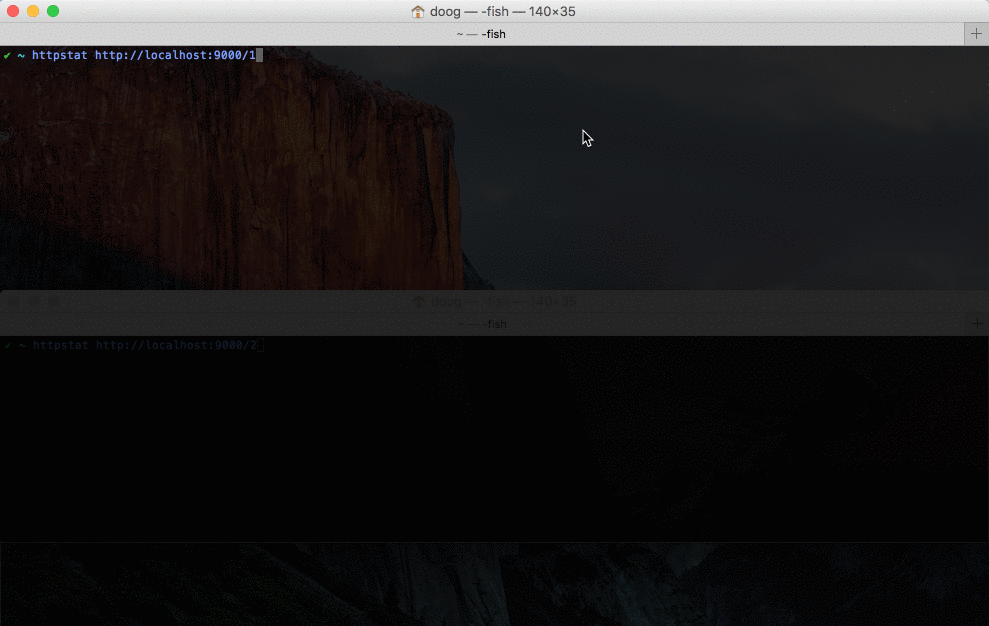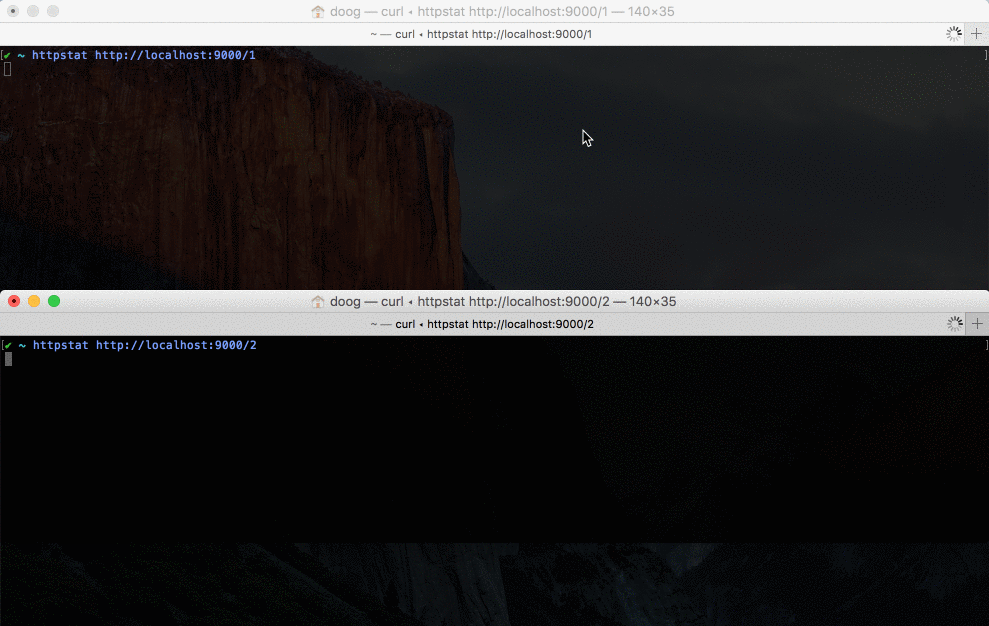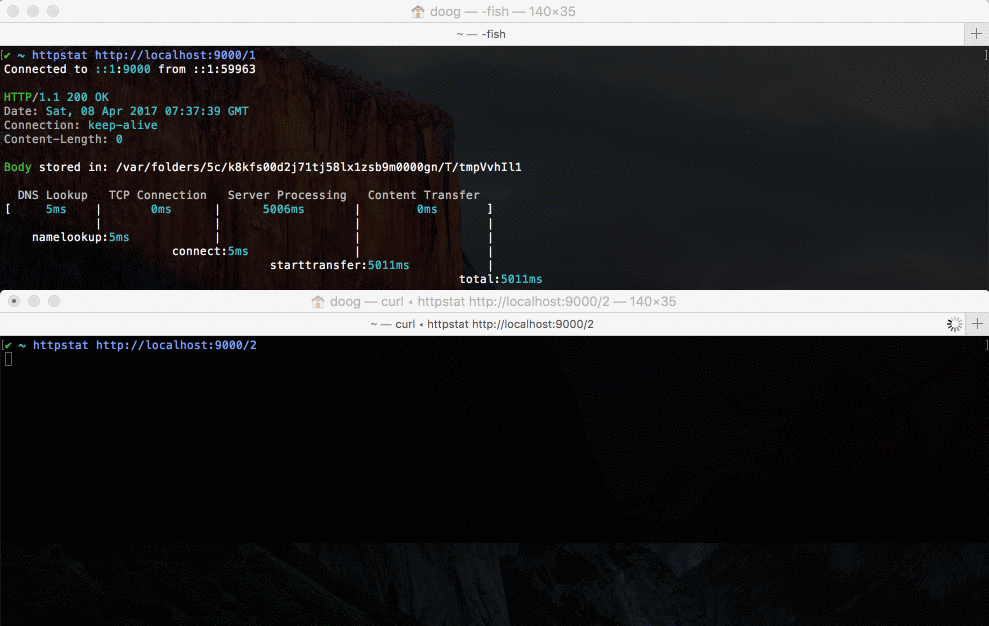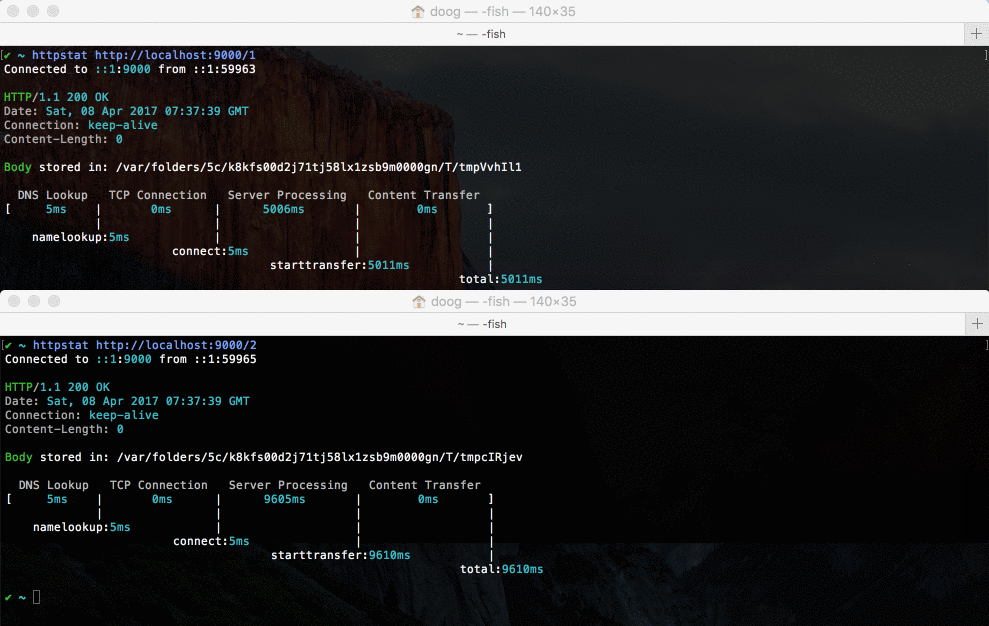
当收到第一个请求后,服务器开始阻塞。此时再发第二个请求,服务器是无法处理请求的。待第一个请求响应后,第二个请求才开始处理。因为它只在一个线程里运行你的代码。
第一个请求 Server Processing 花费大约 5s,第二个花费时间为 9.6s (加上我们手动切换执行的时间,约等于 10s)。从这两个数据可以看出 Node.js 串行的。
我们应该避免在程序里面做大量的计算,CPU 密集型的任务应当避免的。
1 | const http = require('http'); |
Node.js 是单线程的,为什么我们要用它?
下面的例子是根据根据接收到的id,从数据库中拿到数据并返回。我们项目大部分情况做的事情和这个例子是类似的,从前端拿到数据,去数据库做操作。
这里我们需要注意,Node.js 里面的所有IO操作都是异步的。也就是说下面代码中 db.query 是异步执行的。当执行完这一句后,本次 任务 就结束了,服务器就能处理下一个请求了。
一般我们执行 5-9 这块的很快,所以在大部分测试中 Node.js 的并发很高。
很多语言是使用的线程池来处理网络请求,一个线程处理一个请求。线程池的大小往往不会很大。
等 db.query 返回数据后,response 才能拿到数据,然后响应给前端。本次请求就算结束了。
在需要多次操作数据库的业务中,Node.js 相对于其他语言就有些优势了。假设现在有个逻辑是分页,大部分的写法是两次查询数据库。第一次查询count,第二次查询数据。在 Java 正常情况下,发出查询 count 的请求后,会等待数据库返回结果,然后在发出查询数据的请求,最后花费的时间就是二者相加。查询 count 和获取数据并没有依赖关系。如果我们用 Node.js 时,我们可以很简单的并行去发出两个查询。这样花费的时间就是最慢的那个查询。这样,我们的响应就快了。所以在很多对比测试中 Node.js 的 QPS 很高。
1 | /* 1 */ const http = require('http'); |